Creating ‘DATA PRODUCTS’ with GCP BigQuery
In the quest to become a Data Driven Organization, organizations encounter many pitfalls in the form of data silos, separation of transactional and analytical plane and complex ETL pipeline with no End-to-End ownership ultimately leading to creation of Data Swamps thus diminishing the value extracted from data. Data Mesh Architecture promises to solve these issues and deliver maximum value out of the data by fusing operational and analytics plane and offering ‘Data as a Product’ oriented around business domains. You can read more about the Data Mesh here.
However, the underlying technical requirements for creating a ‘DATA PRODUCT’ fusing analytical and operational plane are often contradictory for e.g., Operational plane needs the underlying data store to be a row based transactional database. This should be optimized for reads. However Analytical plane often needs a Data Warehouse which is columnar in nature and should be able to support Petabyte scale data storage. This also means that per unit storage of data should be cheap yet at the same time, there should be no compromise on availability and consistency. Given the large amount of data associated, it should also natively integrate with tools for analysis, visualization and creating machine learning models. Another point worth mentioning is that it should be cloud native to take benefits of elasticity, automation, pay per use, high availability, performance and low-cost storage.
While there are multiple offerings in the market, Google Cloud Platform BigQuery comes close to satisfy the above requirements. BigQuery is GCP’s petabyte scale server less Data Warehouse offering. It separates storage and compute and provide several advanced features as mentioned below which makes it apt to be used to create DATA PRODUCTs as a building block for Data Mesh Architecture.
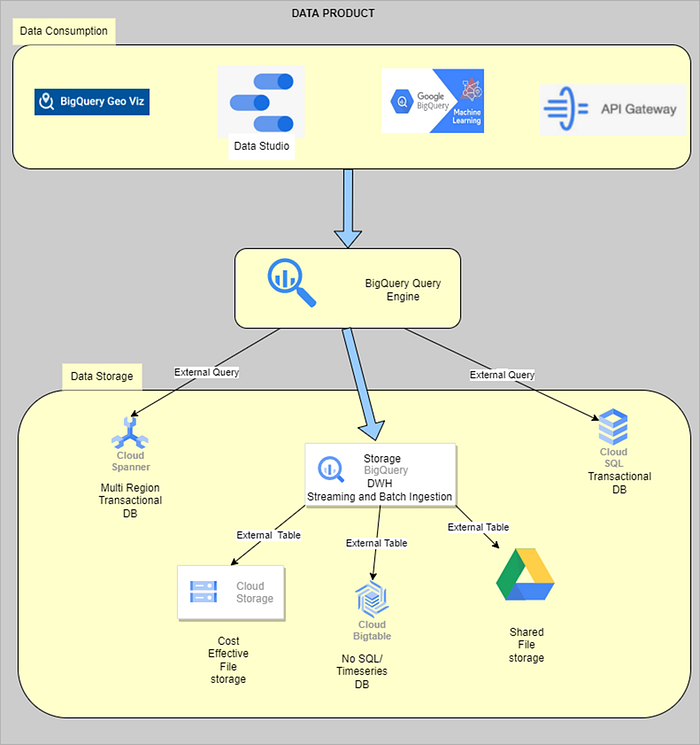
1. BigQuery can access data from external sources, known as federated sources. Instead of first loading data into BigQuery, you can create a reference to an external source. Big query has 2 different mechanisms for querying external data: (a) External tables — An external table is a table that acts like a standard BigQuery table. The table metadata, including the table schema, is stored in BigQuery storage, but the data itself resides in the external source. You can use external tables with BigTable, Cloud Storage and Google Drive. (b) Federated queries — Federated queries are used to access data from Cloud Spanner and Cloud SQL. Federated queries use the BigQuery Connection API to establish a connection with the external database. We can use the EXTERNAL_QUERY function to send a query statement to the external database and receive results in temporary tables with data converted to BigQuery standard SQL data types.
2. While an analytical Data Warehouse stores the data in unnormalized form to make reads efficient, it happens at the cost of storage. Alternative is to store facts and dimensions tables separately and use joins between them to read the data. This is efficient in terms of storage, but queries take longer to serve. BigQuery provides best of both the worlds with its NESTED and REPEATED DATA using RECORD DATA TYPE. Using the RECORD DATA TYPE, we can store data both facts and dimensions in the same table without repeating the dimensional data.
As shown in the table below, order_id, service_type etc fields are not repeated for multiple event status and event time values.

3. To query data efficiently, BigQuery provides lot of in-built analytical functions. Apart from standard aggregation functions like SUM, AVG, GROUP BY etc., it has in built support for LEAD (accessing nth row ahead of the current row), LAG (accessing nth row behind current row), RANK (integer rank of a value in a group), ROW_NUMBER etc.
4. BigQuery supports data ingestion using both batch and streaming modes. ‘Streaming Inserts’ allow you to insert one row at a time and also supports de-duplication of data by using insertID while ingesting. BigQuery streaming inserts provides latency in the order of seconds with throughput as high as 100K rows/second streaming or 100 MB with deduplication.
5. BigQuery supports inbuilt ML for training ML models — BigQuery ML is a feature of the BigQuery that allows SQL developers to build machine learning models in BigQuery using SQL. This provides ability to create machine learning models on structured data as it is available in BigQuery without the need for extracting the data explicitly for training machine learning models. It also provides ability to evaluate the trained models and predict using the trained models. Moreover, we can also import custom tensor flow models into BigQuery and use the same to predict.
6. BigQuery support User Defined Functions using SQL expressions or JavaScript to perform transformations. UDFs can use built-in SQL functions. UDFs can be shared with other team members.
7. BigQuery supports GIS functions such as ST_DWithin, ST_geoPoint, ST_makeline etc. These functions help us to point a geographic location and find distance between 2 geo-locations or check if a point is within or outside a polygon made by geo-coordinates. These functions also allow us to find whether a location is within certain distance from the geo-spatial boundaries of a zip code. Also using BigQuery GeoViz application, we can render GIS data with minimal configuration and draw line, polygons, and geo-locations of interest.
8. Apart from Interactive and batch SQL queries, BigQuery integrates natively with Google Data Studio to create visualization and dashboards off the data in BigQuery. BigQuery BI engine can be used to further enhance the performance of the dashboards. BigQuery BI engine is a fast, In-Memory intelligent caching service built directly into BigQuery to speed up the Business Intelligence applications.
9. Partition and clustering — BigQuery supports the concept of dividing table into segments called Partitions using ingestion time or timestamp-based column or integer range-based column. This makes the queries efficient by scanning only the required partitions. Another concept that BigQuery supports is Clustering which is ordering of data in stored format. This allows BigQuery to efficiently retrieve data against filtering and aggregating queries.
10. BigQuery supports petabyte level scale with cost comparable to Cloud Storage. Stored data in BigQuery data is considered active if it was referenced in the last 90 days; otherwise, it is considered long-term data. The charge for long-term storage in BigQuery is approximately equal to the cost of Nearline Cloud Storage (Nearline Storage is a tier of Cloud Storage used for data accessed less than once in 30 days). BigQuery storage is costed and scaled separately from compute (Query Engine).
Let’s say that we are creating a Data Mesh for a multi-national e-commerce organization, and we need to create an ‘Orders’ DATA PRODUCT. Typical requirements would be to save the order as it progress from ‘placed’ to ‘delivered’ status. Once the order is delivered, we want to use it for analytical purpose. We also want to perform geo-based analysis e.g., how many orders are placed within 2 kms of a zip code. We also want to perform some machine learning to produce Recommendations for the users and lastly for some of the high value orders, the organization attaches a sensor to track the delivery in real time basis. The sensor generates high frequency time series data sending the location of the item in real time.
For the above requirements, the initial order details can be stored in Cloud Spanner (as it is a multi-regional) RDBMS. Once the order is delivered; it can be moved to BigQuery storage for analytics. We can leverage BigQuery ML to create recommendation model. Also, the BigQuery Geo Viz can be used to perform geo-based analytics. For tracking the order delivery in real time, we can leverage BigTable to store time series Data. Data Studio can be leveraged to provide the visualization and dashboards for the data. We can provide API to access these data as well. All these data stores can be queried using BigQuery query engine. BigTable, Cloud Storage and Google Drive can be accessed by creating an External Table in Big Query. Here the table metadata, including the table schema, is stored in BigQuery storage, but the data itself resides in the external source. Data Stored in Cloud Spanner and Cloud SQL can be accessed using federated query. Here we can use BigQuery Connection API to establish the connection with Cloud Spanner and Cloud SQL, use EXTERNAL_QURY function to send a query statement and get their results as temporary tables with results converted into BIG Query standard Data types.
A single domain-oriented team will be in-charge of the ‘Orders DATA PRODUCT’. The team will leverage the underlying Google Cloud platform to provision and maintain the DATA PRODUCT (given the use of cloud native technologies). This also aligns to other principles of Data Mesh.